笔者在之前的面试中遇到过“一次性给你 10000 条数据,怎么让它不卡之类的问题“,当初准备不充分,不知道怎么回答这类问题,说的方案过于简单,还扯到防抖节流之类的性能优化点上,这篇文章原本2022年1月29日计划写,后因春节过年耽误,直至近日动笔
查阅资料后发现有三种解决方案:
- 虚拟列表(也叫按需渲染或可视区域渲染)
- 延迟渲染(即懒渲染)
- 时间分片
虚拟列表是最主流的解决方案,不渲染所有的数据,只渲染可视区域中的数据。当用户滑(滚)动时,通过监听 scroll 来判断是上滑还是下拉,从而更新数据。同理 IntersectionObserver 和 getBoundingClientRect 都能实现
延迟渲染,也叫懒加载。顾名思义,最开始不渲染所有数据,只渲染可视区域中的数据(同虚拟列表一致)。当滚动到页面底部时,添加数据(concat),视图渲染新增DOM
时间分片主要是分批渲染DOM,使用 requestAnimationFrame 来让动画更加流畅
先说最主流的方案
虚拟列表
什么是虚拟列表
虚拟列表是按需显示的一种实现,即只对可见区域进行渲染,对非可见区域中的数据不渲染或部分渲染的技术,是对长列表渲染的优化手段
说的明白一点,就是展示可视区域中的内容,当你向上向下滚动时,通过 DOM API 替换可视区域中的数据,做到动态加载十万条数据
两种解决思路
关于无限滚动,早期通过监听 scroll 事件,这是最常见的解决方案。可去 图片懒加载 中查看,简单来说,就是通过子项的 offsetTop(偏移高度)与 innerHeight(视窗高度)+ scrollTop(滚动高度)做对比来实现,当偏移高度 < 视窗高度+滚动高度时,说明已经滚到下方,就可展示图片
在 图片懒加载 中我们也提及 IntersectionObserver(交叉观察者)API,以此来解决 scroll 所不具备的效果,即 IntersectionObserver API 是异步的,不随目标元素的滚动同步触发,性能消耗小。当然还可以通过 getBoundingClientRect 来实现,getBoundingClientRect 方法返回元素的大小机器相对于视窗的位置
PS:所以目前来说有三种方法,在文末 demo 中会附上单独使用这三种解决方案的代码
在这里,因本人实力有限,未破解 getBoundingClientRect 向上滑动时的页面抖动问题,只有 scroll 和 IntersectionObserver 两种解决方案(getBoundingClientRect 方法也放在代码中,但向上滑动会抖动)
先说 scroll 解决方案,简单来说,就是对其传来的数据进行分割展示,用到 slice 方法,它会返回一个新的数组
我们假设单个列表高度为 30px,一页展示的列表数量为 const count = Math.ceil(列表高度 / 30),展示的数据就是 visibleData = data.slice(start, start + count)(start 一开始为0)
当滚动时,动态修改 start 和 visibleData
import React, { useEffect, useState, useRef } from "react";
const VirtualList = (props) => {
const { data } = props;
const [start, setStart] = useState(0);
const [visibleCount, setVisibleCount] = useState(null);
const [visibleData, setVisibleData] = useState([]);
const virtualRef = useRef(null);
const virtualContentRef = useRef(null);
useEffect(() => {
const count = Math.ceil(virtualRef.current.clientHeight / 30);
setVisibleCount(count);
setVisibleData(data.slice(start, start + count));
}, []);
const onHandleScroll = () => {
const scrollTop = virtualRef.current.scrollTop;
const fixedScrollTop = scrollTop - (scrollTop % 30);
virtualContentRef.current.style.webkitTransform = `translate3d(0, ${fixedScrollTop}px, 0)`;
setStart(Math.floor(scrollTop / 30));
setVisibleData(data.slice(start, start + visibleCount));
};
return (
<div className="virtual-list" ref={virtualRef} onScroll={onHandleScroll}>
<div
className="virtual-list-phantom"
style={{ height: data.length * 30 + "px" }}
></div>
<div className="virtual-list-content" ref={virtualContentRef}>
{visibleData.map((item) => (
<div className="virtual-list-item" key={item.key}>
{item.key}
{item.value}
</div>
))}
</div>
</div>
);
};
export default VirtualList;
注:virtual-list-phantom 会让滚动条看起来很高,个人认为有无都不影响观感
(有virtual-list-phantom)效果如下:
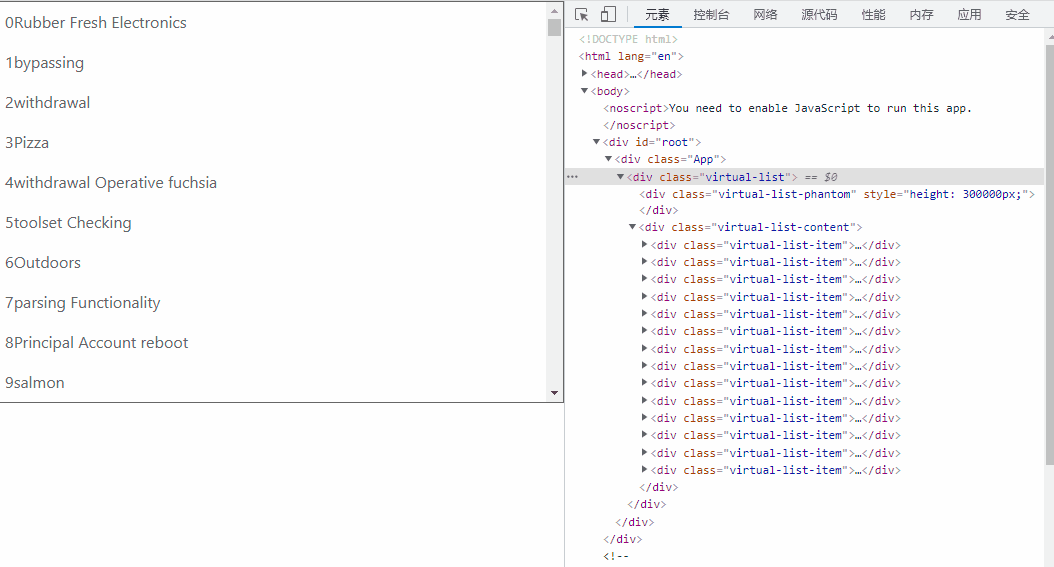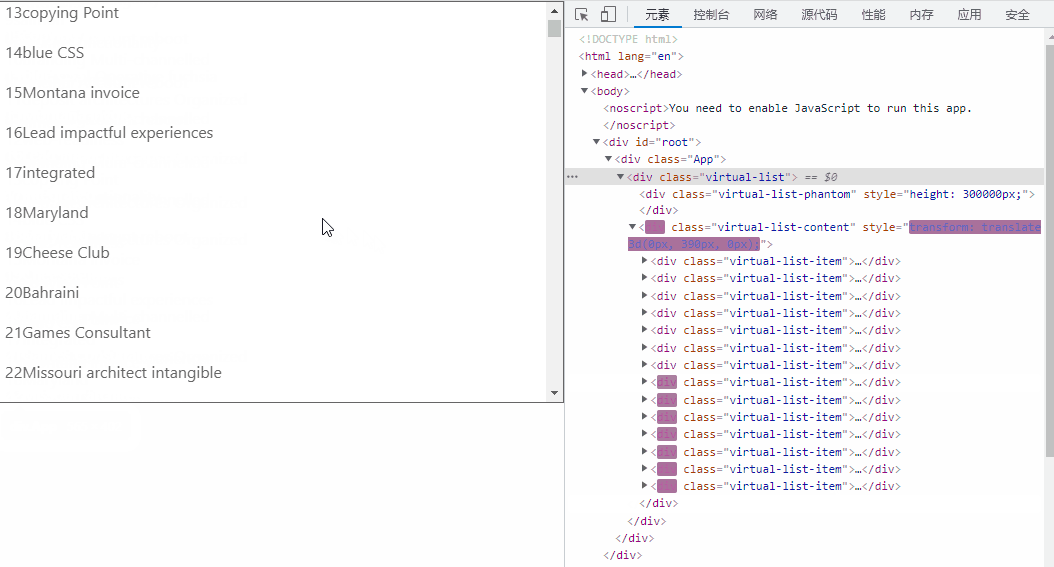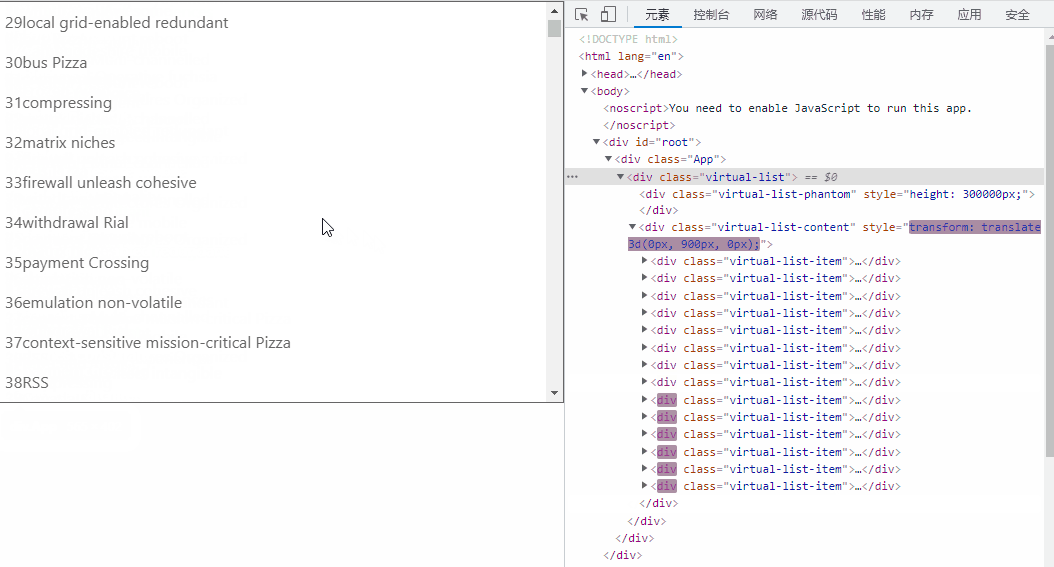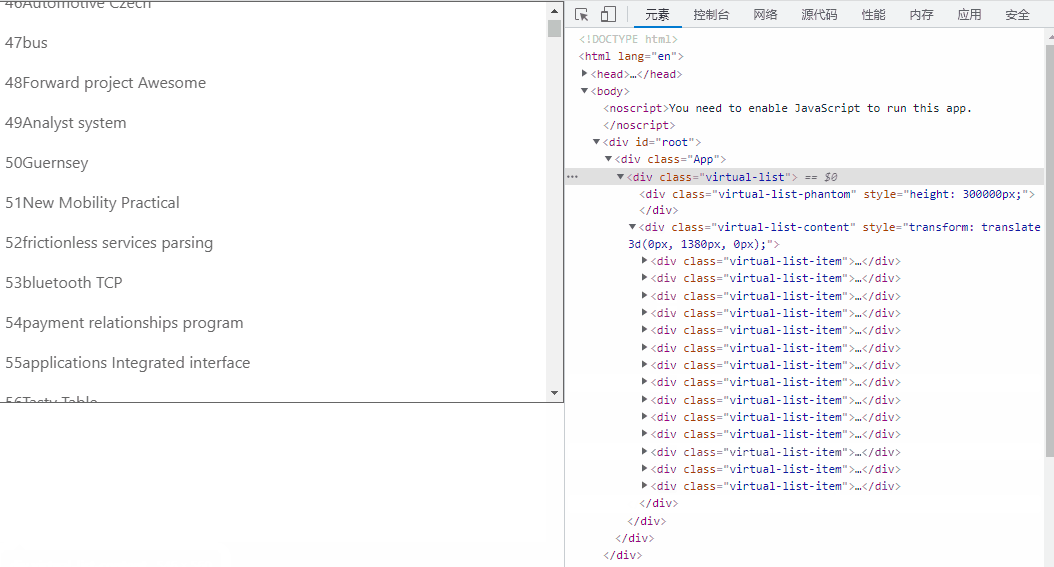
(无virtual-list-phantom)效果如下:
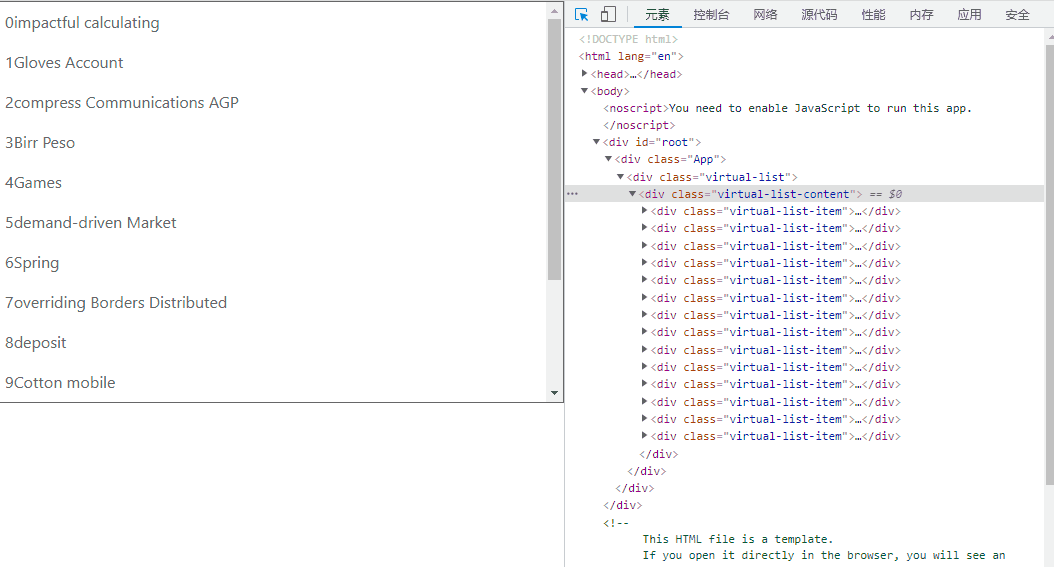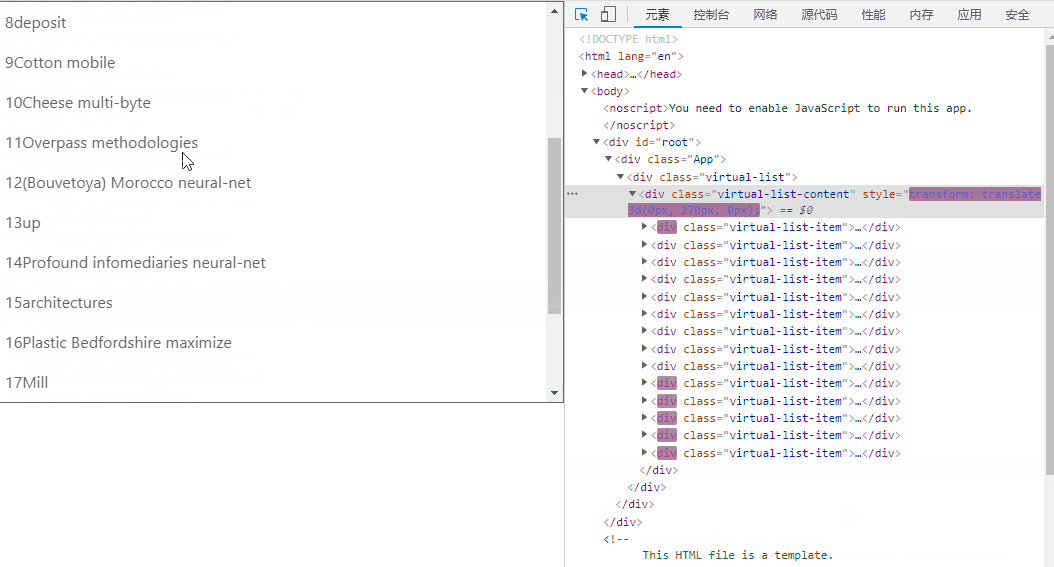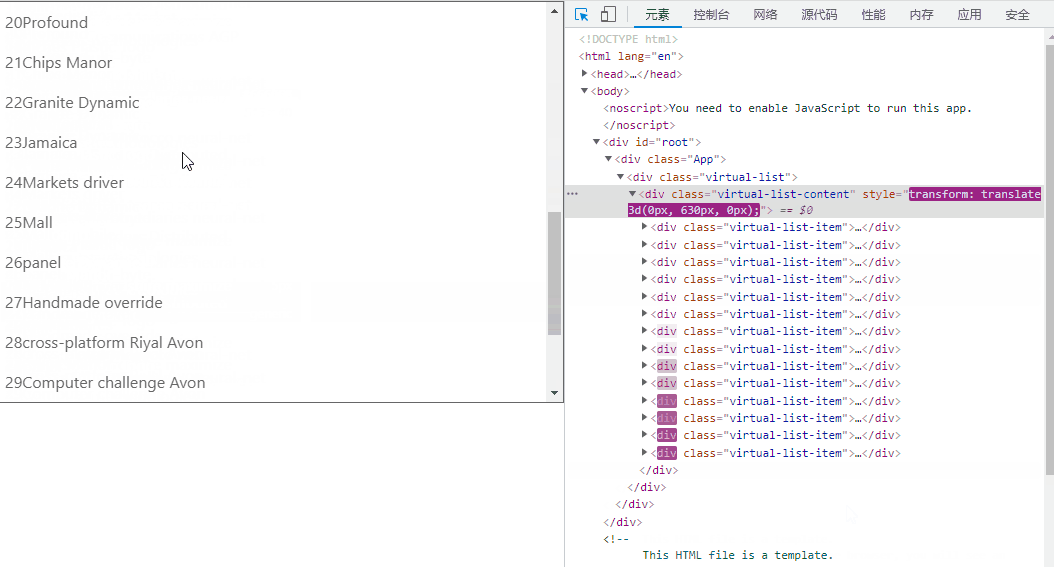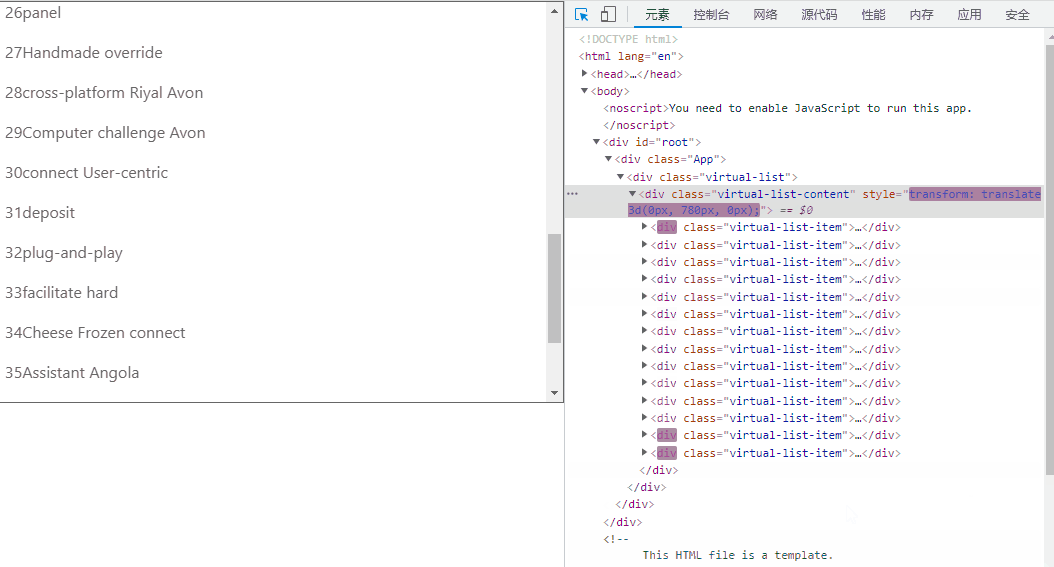
这种方法的精髓在于设置开始渲染的点和展示的数据,当他滚动时动态修改,但是因为 scroll 会频繁触发,当渲染的数据变多后会有性能问题
IntersectionObserver 解决方案
通过 IntersectionObserver 的特性,当目标对象中的 entry.isIntersecting 为 true 或者 intersectionRatio > 0 (元素与祖先元素交叉、可见)时,说明本来不可见的元素浮现在视图中,表示它向上或向下滑动,我们动态设置视图中的顶部和底部 id 即可对其判断。当下滑时 entry.traget.id === 'bottom',我们修改 start 和 end;同理,当上滑时entry.traget.id === 'top 时,我们也一样修改 start 和 end
附上部分代码:
...
const [start, setStart] = useState(0);
const [end, setEnd] = useState(THRESHOLD);
const [observer, setObserver] = useState(null);
const bottomElement = useRef();
const topElement = useRef();
...
const Observer = new IntersectionObserver(callback, options);
const callback = (entries, observer) => {
entries.forEach(entry => {
const dataLength = data.length;
if (entry.isIntersecting && entry.target.id === "bottom") {
const maxStartIndex = dataLength - 1 - THRESHOLD;
const maxEndIndex = dataLength - 1;
const newStart = end - 5 <= maxStartIndex ? end - 5 : maxStartIndex;
const newEnd = end + 10 <= maxEndIndex ? end + 10 : maxEndIndex;
setStart(newStart);
setEnd(newEnd);
}
if (entry.isIntersecting && entry.target.id === "top") {
const newEnd =
end === THRESHOLD
? THRESHOLD
: end - 10 > THRESHOLD
? end - 10
: THRESHOLD;
const newStart = start === 0 ? 0 : start - 10 > 0 ? start - 10 : 0;
setStart(newStart);
setEnd(newEnd);
}
});
};
const updatedList = data.slice(start, end);
return (
<div style={{ position: "relative", textAlign: "center" }}>
{updatedList.map((item, index) => {
const top = height * (index + start) + "px";
const refVal = getReference(index, index === lastIndex);
const id = index === 0 ? "top" : index === lastIndex ? "bottom" : "";
return (
<div
className="io-virtual-list-item"
key={item.key}
style={{ top }}
ref={refVal}
id={id}
>
{item.key}
</div>
);
})}
</div>
);
...
效果如下:
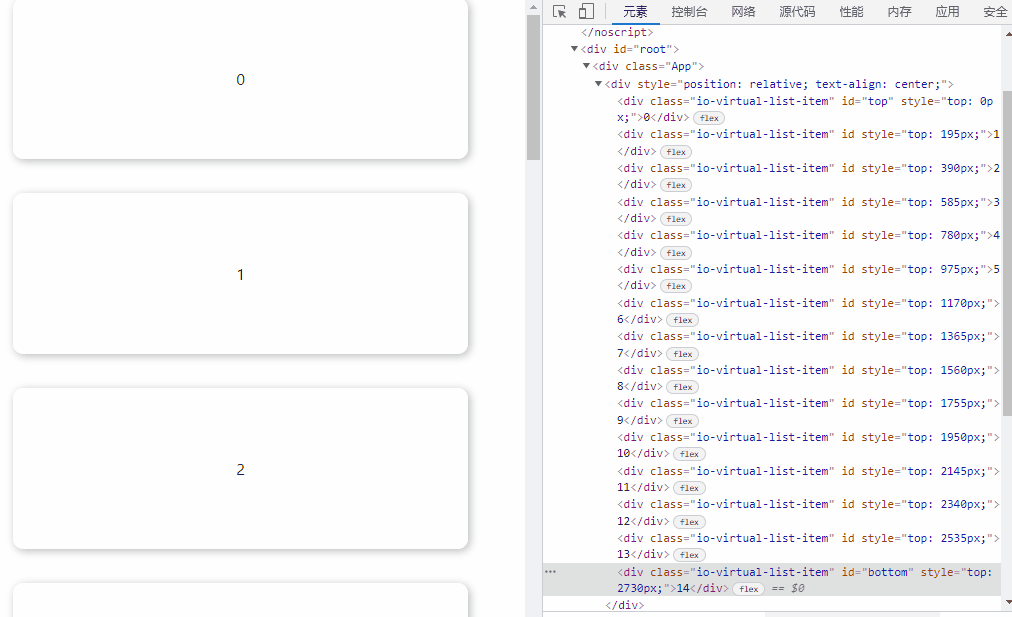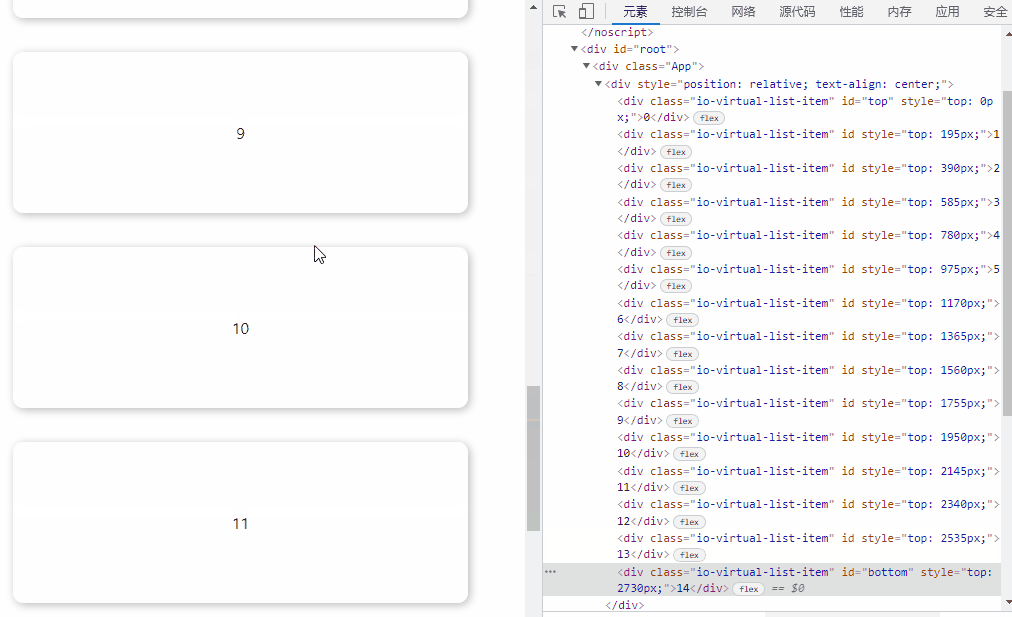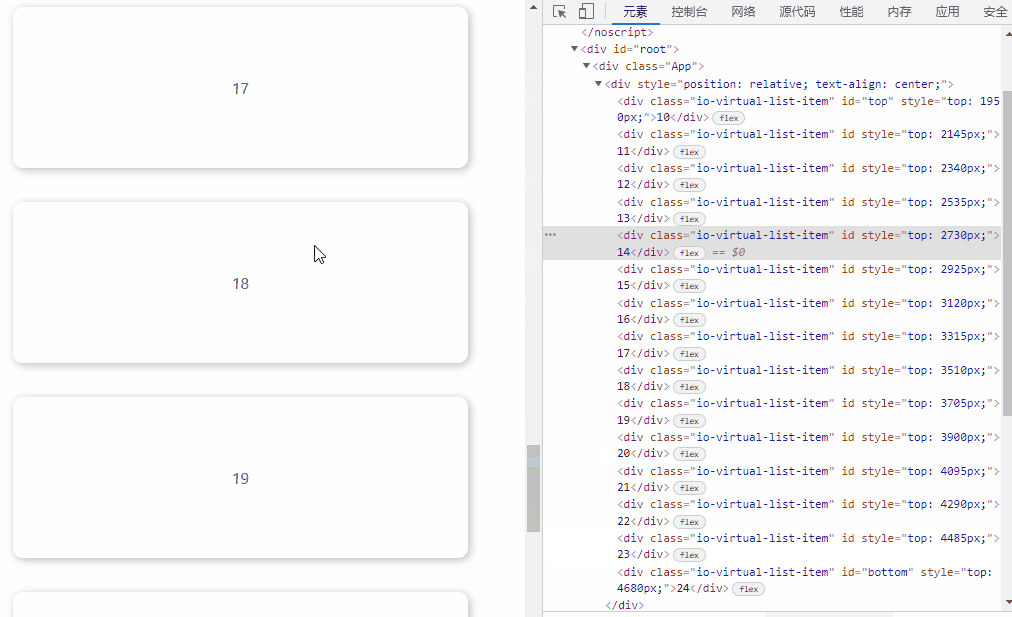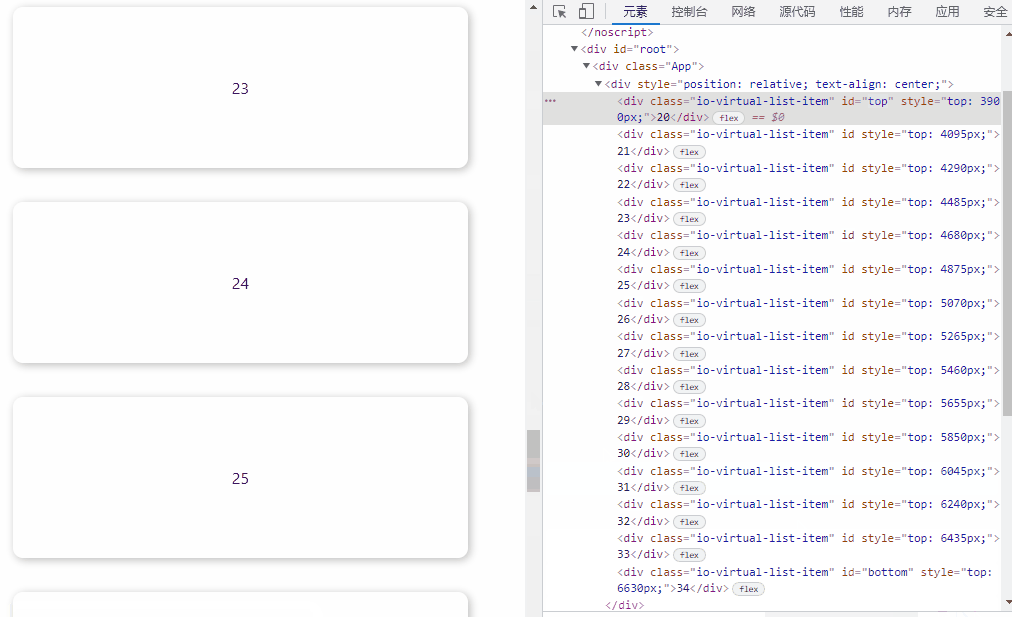
推荐用这种方法,IntersectionObserver 是异步 API,性能消耗小,缺点是有些落后浏览器不支持,如公司需要兼容这类用户,需引入 polyfill
懒加载
不多介绍,一句话解释:最开始不渲染所有数据,只展示视图上可见的数据,当滚动到页面底部时,加载更多数据
实现原理:通过监听父级元素的 scroll 事件,当然也可以通过 IntersectionObserver 或 getBoundingClientRect 等 API 实现
但 scroll 事件会频繁触发,所以需要手写节流;滚动元素内有大量 DOM ,容易造成卡顿,建议使用 IntersectionObserver
因为之前在讲 图片懒加载 时说过思路,这里就不贴,文末会附上demo
时间分片
参考 如何高性能的渲染十万条数据(时间分片) 所举例子,对于大量数据渲染时,JS 运算并不是性能的瓶颈,性能的瓶颈主要在于渲染阶段。也就是说 JS 执行是很快的,页面卡顿是因为同时渲染大量 DOM 所引起的,可采用分批渲染的方式来解决
let ul = document.getElementById("container");
// 插入十万条数据
let total = 100000;
// 一次插入 20 条
let once = 20;
// 总页数
let page = total / once;
// 每条记录的索引
let index = 0;
// 循环加载数据
function loop(curTotal, curIndex) {
if (curTotal <= 0) {
return false;
}
// 每页多少条
let pageCount = Math.min(curTotal, once);
setTimeout(() => {
for (let i = 0; i < pageCount; i++) {
let li = document.createElement("li");
li.innerText = curIndex + i + " : " + ~~(Math.random() * total);
ul.appendChild(li);
}
loop(curTotal - pageCount, curIndex + pageCount);
}, 0);
}
loop(total, index);
我的理解是,通过递归来渲染DOM,刚开始可以是20个,20个渲染完后再渲染剩下的,循环如此,将其全部渲染完。又因为浏览器的渲染机制是“宏任务—微任务—GUI渲染—宏任务…”。遂第一个 loop 执行后,先等页面渲染完,再执行下一轮的 setTimeout(宏任务)
使用 setTimeout 来做分片会有问题,就是当我们快递下拉时,会出现闪屏或白屏现象?
这是因为人眼识别帧数为24帧。当帧数为24帧时,连续的画面会形成动画,老一辈的动画片,例如《大闹天空》《哪吒闹海》之类都是一秒里有24个画面(24帧),平滑动画的最佳循环间隔就是 1000 / 24,约等于 41.67ms
而电脑显示器的刷新频率为 60 帧,大概相当于每秒重绘 60 次。同理,如果想骗过人眼,平滑动画的最佳循环时间就是 1000 / 60,约等于 16.7ms
而 setTimeout 的执行时间并不是确定的,虽然我们写了 setTimeout(() => {}, 0) ,但这是不准确的,按照 H5 标准规定 setTimeout 的第二个参数不能小于 4ms,不足会自动增加
所以当第一个宏任务完成,第一个微任务完成,第一次渲染页面后,4 毫秒后再执行第二个宏任务,这样就导致了实际执行时间慢了 4 毫秒,当一个周期(宏任务+微任务+GUI渲染+4ms)的总和时间大于16.7ms,就会出现掉帧现象,这也是为什么 React 要使用 Fiber 架构的原因
加上各类电子设备的刷新频率不同,也会导致一个周期的总时间大于16.7ms
requestAnimationFrame 正是解决这一问题的关键API,它告诉浏览器——你希望执行一个动画,并且要求浏览器在下次重绘之前调用指定的回调函数更新动画。
因为他是浏览器所提供的原生 API,所以各类电子设备都能使用,根据不同的刷新频率,给于不同的动画执行时间,就不会引起丢帧现象
...
function loop(curTotal, curIndex) {
if (curTotal <= 0) {
return false;
}
// 每页多少条
let pageCount = Math.min(curTotal, once);
window.requestAnimationFrame(function () {
for (let i = 0; i < pageCount; i++) {
let li = document.createElement('li');
li.innerText = curIndex + i + ' : ' + ~~(Math.random() * total)
ul.appendChild(li)
}
loop(curTotal - pageCount, curIndex + pageCount)
})
}
loop(total, index);
总结
渲染十万条数据有三种解决方案,为虚拟列表、懒加载、时间分片。最优选是虚拟列表,DOM 树上只挂载有限的DOM;懒加载和时间分片的缺点在于插入大量的DOM,占内存运行时会造成卡顿
无论是虚拟列表还是懒加载,传统的做法是 scroll + 节流,这种做法的优势是老 API,兼容性刚刚的,缺点是,滑多了还是会引起性能问题,当然 IntersectionObserver 也是一样的,无非是换了个 API 做“元素是否出现在视图”判断,最好的方案是用 IntersectionObserver(交叉观察器),异步加载、性能消耗小
附上线上demo示例:
参考资料