学习一项知识,必须问自己三个重要问题:1. 它的本质是什么。2. 它的第一原则是什么。3. 它的知识结构是怎样的
测试一下 Hooks 的熟练程度
为什么不能在 for 循环、if 语句里使用 Hooks
React.memo、React.useCallback、React.usememo 的作用,以及对比
useState 中的值是个对象,改变对象中的值,组件会渲染吗?如果用 React.memo() 包裹住呢
Hooks 的(实现)原理是什么?
Hooks 的本质是什么?为什么?
React Hooks,它带来了哪些便利?
React Hooks 当中的 useEffect 是如何区分生命周期钩子的
useEffect(fn, []) 和 componentDidMount 有什么差异
回答得如何?在了解一个概念前,疑惑越多,理解就越深
是什么
React Hooks 是 React 16.8 推出的新特性。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性
为什么会有 Hooks
我们一定要有个概念,即 React 的本质是什么?它的特征是 UI=f(data)、一切皆组件、声明式编程。那么,既然是 UI=f(data),data(数据)通过 function 来驱动 UI 视图变化。在业务中,你不能简单只展示,也需交互,交互就会更新状态,React 是通过 setState 来改变状态。但这仅限于类组件,所以在Hooks出现之前,函数式组件用来渲染组件(也称它为木偶组件),类组件用来控制状态
而后,为了让状态能更好的复用,提出了Mixins 、render props 和 高阶组件。诚然,render props、高阶组件能虽然能解决,但是会带来副作用——组件会形成“嵌套地狱”
以及类组件本身的生命周期会使得复杂的组件变得难以理解、class 语法的学习成本等等,构成了React 团队提出 hooks——让函数式组件拥有状态管理
官网也阐述过设计Hooks的三大动机:
- 在组件之间复用状态逻辑很难
- 复杂组件变得难以理解
- 难以理解的 class
状态复用的实验
Mixins时代
在笔者尚未使用 React 之前就存在,现已被淘汰
Mixins(混入)是一种通过扩展收集功能的方式,它本质上是将一个对象的属性拷贝到另一个对象上,不过你可以拷贝任意多个对象的任意个方法到一个新对象上去,这是继承所不能实现的。它的出现主要就是为了解决代码复用问题
这里不对其做分析,React官方文档在 Mixins Considered Harmful 一文中提到了 Mixins 带来的危害:
- Mixins 可能会相互依赖,相互耦合,不利于代码维护
- 不同的 Mixins 中的方法可能会相互冲突
- Mixins 非常多时,组件是可以感知到的,甚至还要为其做相关处理,这样会给代码造成滚雪球的复杂性
Render Props
指一种在 React 组件之间使用一个值为函数的 prop 共享代码的简单技术
具有 render prop 的组件接受一个返回 React 元素的函数,并在组件内部通过调用此函数来实现自己的渲染逻辑
<DataProvider render={data=> (
<h1>Hello, {data.target}</h1>
)}>
具体可在官网了解
HOC(高阶组件)
HOC的原理其实很简单,它就是一个函数,并且它接受一个组件作为参数,并返回一个新的组件,把复用的地方放在高阶组件中,你在使用的时候,只需要做不同用处
打个比方:就好像给你一瓶水,你在渴的时候就会喝它;你在耍帅的时候拿它摆POSE;你在别人需要的时候给他喝帮助人…
Writing is cheap. Show me code
function Wrapper(WrappedComponent) {
return class extends React.Component {
componentDidMount() {
console.log("我是一瓶水");
}
render() {
return (
<div>
<div className="title">{this.props.title}</div>
<WrappedComponent {...this.props} />
</div>
);
}
};
}
import "./styles.css";
import React from "react";
import Wrapper from "./Wrapper";
class A extends React.Component {
render() {
return <div>喝它</div>;
}
}
class B extends React.Component {
render() {
return <div>耍帅摆POSE</div>;
}
}
class C extends React.Component {
render() {
return <div>帮助别人</div>;
}
}
const AA = Wrapper(A);
const BB = Wrapper(B);
const CC = Wrapper(C);
export default function App() {
return (
<div className="App">
<h1>Hello CodeSandbox</h1>
<h2>Start editing to see some magic happen!</h2>
<AA title="我是普通人" />
<BB />
<CC />
</div>
);
}
这样就很明显的看出 HOC 的好处,”一瓶水“是共同代码,A、B、C处理业务代码,然后将A、B、C传入HOC(一瓶水)中,返回了一个新的组件 AA、BB、CC。相同的代码得到了公用
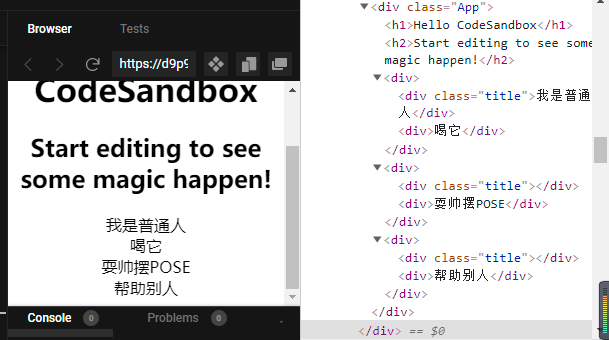
各位可以前往这里查看 demo
HOC 的用处不单单是代码复用,还可以做权限控制、打印日志等。但它的缺陷也没明显,当大量使用 HOC 后,会产生大量的嵌套,使得嵌套变得困难;并且 HOC 会劫持 props,在不遵守约定的情况下可能会造成冲突
总结下 HOC:
- 用法:创建一个函数,该函数接收一个组件作为输入,除了组件还可以传递其他的参数,基于该组件返回一个不同的组件
- 优点:代码复用,逻辑复用
- 缺点:因为嵌套使得调试难度变高;会劫持props,或许造成冲突
Hooks 的出世
前有状态复用的不给力( Mixins 被淘汰,render props、HOC 的副作用又大),后有类组件的复杂组件难以理解、维护(过多的生命周期),class 属性造成的 this 指向又麻烦。于是乎,Hooks 大喊一声:我来也
它起码有三个好处
useState
作用:让函数组件具有维持状态的能力,替代类组件的constructor初始化状态
例子:
const Counter = () => {
const [count, setCount] = useState(0);
return <div onClick={() => setCount(count + 1)}>{count}</div>;
};
特点:逻辑复用
在使用 useState 时,会出现两个衍生问题:
一:Capture Value 特性
在函数式组件与类组件有何不同中曾介绍过,函数式组件能捕获渲染时所用的值。并举例组件中点三下加, setTimeout 3秒后弹出数字,在点两次加,3秒后展示3,而不是5。而类组件却能获得最新的数据,这是为什么?
因为函数式组件有 Capture Value 的特性。而从源码的角度看,每次调用 setXX 会引发 re-render 从而重渲染组件
如果想获得最新值,可以通过 useRef 来将值保存在内存中
二:useState 中的值是个对象,改变对象中的值,组件会渲染吗?怎么优化?
一般我们用 useState 尽量遵守单一值,但难免会遇到一些特殊情况,如果值是个对象,改变对象中的其中一个属性,其他属性不变,那么引用其他属性的组件是否会渲染呢?
const DemoSon = (props) => {
console.log("render", props);
return <div>{props.name}</div>;
};
const Demo = () => {
const [data, setData] = useState({ foo: { name: "johan", bar: { baz: 1 } } });
const handleClick = () => {
setData({
...data,
foo: {
...data.foo,
bar: {
baz: 2,
},
},
});
};
return (
<div onClick={handleClick}>
{data.foo.bar.baz}
<DemoSon name={data.foo.name} />
</div>
);
};
点击 div,修改 baz 的值,DemoSon 是否会渲染呢?答案是会的,为什么会渲染?因为你的引用值发生了变化,生成了新的虚拟DOM,渲染到视图上时,子组件就会渲染。如何优化,让数据不变的组件不重复渲染?我觉得有两种方式,一拆分 data,拆分成 foo 对象和name,因为 setData 并不改变 name,所以DemoSon 不会渲染,还有一种是通过 memo 包裹住 DemoSon,因为 memo 能避免重新渲染
可查看线上 demo
useEffect
作用:处理副作用,替代类组件的componentDidMount、componentDidUpdate、componentWillUnmount
使用方式:
// 没有第二个参数
// mount 阶段和 update 阶段都执行
useEffect(fn);
// 第二个参数为空数组
// 当 mount 阶段会执行
useEffect(fn, []);
// 第二个参数为依赖项
// 当依赖项(deps)数据更新时会执行
useEffect(fn, [deps]);
// 清除副作用
useEffect(() => {
const subscription = props.source.subscribe();
return () => {
// 清除订阅
subscription.unsubscribe();
};
});
PS:以上注释中的 mount 阶段,即组件加载时;update 指数据(包括props、state)变化时
在使用 useEffect 时,会面临几个问题:
1. useEffect(fn, []) 和 componentDidMount 有什么区别?
虽然 useEffect(fn, []) 和 componentDidMount 都可以表示组件加载时执行,但从细节上两者有所不同。要谈起细节需从源码中聊起,具体可看 React 源码魔术师卡颂的这篇——useEffect(fn, [])和cDM有什么区别? 了解,这里我讲下我的理解
源码中把虚拟DOM和虚拟DOM渲染到真实DOM分为两个阶段。虚拟DOM存在内存中,在 JSX 中对数据增删改,虚拟DOM会对对应的数据打上标签,这个阶段称为 render 阶段;把虚拟DOM映射到真实DOM的操作被称为 commit 阶段,它负责把这些标签转换为具体的DOM操作
在 render 阶段
- 插入 DOM 元素被打上 Placement 标签;
- 更新 DOM 元素被打上 Update 标签;
- 删除 DOM 元素被打上 Deletion 标签;
- 更新 Ref 属性被打上 Ref 标签
- useEffect 回调被打上 Passive 标签
而 commit 阶段分为三个子阶段
- 渲染视图前(before mutation 阶段)
- 渲染视图时(mutation 阶段)
- 渲染视图后(layout 阶段)
被打上 Placement 标签的,会在 mutation 阶段时执行对应的 appendChild 操作,意味着 DOM 节点被插入到视图中,接着在 layout 阶段调用 componentDidMount
而被打上 Passive 标签的,它会在 commit 阶段的三个子阶段执行完成后再异步调用 useEffect 的回调函数
由此可见,它们的调用调用时机是不同的,useEffect(fn,[]) 是在 commit 阶段执行完以后异步调用回调函数,而 componentDidMount 会在 commit 阶段完成视图更新(mutation阶段)后再 layout 阶段同步调用
hooks 中也有一个和 componentDidMount 调用时机相同的 hooks——useLayoutEffect
其次useEffect(fn, []) 会捕获 props 和state,而 componentDidMount 并不会。使用 useEffect(fn, []) 的会第哦啊函数会拿到初始的 props 和 state,这个道理和 capture value 是一个道理
总结:两点不同,一、执行时机不同;二、useEffect(fn, []) 会对 props 和 state 进行捕获
下文会用demo说明 capture value 特性
2. 每一次渲染都有它自己的 props 和 state
先讨论一下渲染(rendering),我们来看一个计数器组件 Counter
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<p>点击 {count} 次</p>
<button onClick={() => setCount(count + 1)}>点击</button>
</div>
);
}
第一次渲染时,count 的初始值从 useState(0) 中获取。当调用 setCount(count + 1) ,React 重新渲染组件,此时 count 的值就成 1。如下所示:
// Mount 第一次渲染
function Counter() {
const count = 0; // 默认从useState 中获得
// ...
<p>点击 {count} 次</p>;
// ...
}
// Update 点击 1 次
function Counter() {
const count = 1; // 通过 setCount 修改 count
// ...
<p>点击 {count} 次</p>;
// ...
}
// Update 点击 2 次
function Counter() {
const count = 2; // 通过 setCount 修改 count
// ...
<p>点击 {count} 次</p>;
// ...
}
每当我们更新状态时,React 会重新渲染组件。每次渲染获得此刻(快照)的 count 状态
而在类组件中并不是捕获值
举个例子:
class ClassDemo extends React.Component {
state = {
count: 0,
};
componentDidMount() {
setInterval(() => {
this.setState({ count: this.state.count + 1 });
}, 1000);
}
render() {
return <div>我是Class Component, {this.state.count}</div>;
}
}
页面上的 count 会每隔一秒钟加1,而换成函数式组件
const FunctionDemo = () => {
const [count, setCount] = useState(0);
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, []);
const handleClick = () => {
setCount(count + 1);
};
return <div onClick={handleClick}>我是Function Component, {count}</div>;
};
永远是1
这就是 hooks 的capture value,类似例子在函数式组件与类组件有何不同介绍过
可前往线上demo查看
useLayoutEffect
作用:同步执行副作用
大部分情况下,使用 useEffect 就可以帮我们处理副作用,但是如果想要同步调用一些副作用,比如对 DOM 的操作,就需要使用 useLayoutEffect,useLayoutEffect 中的副作用会在 DOM 更新之后同步执行
与类组件中的 componentDidMount 效果一致,都是在 commit 阶段完成视图更新(mutation阶段)后在 layout阶段同步调用
useCallback
作用:记忆函数,避免函数重新生成。在函数传递给子组件时,可以避免子组件重复渲染
例子:
const memoizedCallback = useCallback(() => {
doSomething(a, b);
}, [a, b]);
可缓存的引用
在类组件中常困扰人的是 this 绑定问题
- render 方法中使用bind
class App extends React.Component {
handleClick() {
console.log("this > ", this);
}
render() {
return <div onClick={this.handleClick.bind(this)}>test</div>;
}
}
- render方法中使用箭头函数
class App extends React.Component {
handleClick() {
console.log("this > ", this);
}
render() {
return <div onClick={(e) => this.handleClick(e)}>test</div>;
}
}
- 构造函数中bind
class App extends React.Component {
constructor(props) {
super(props);
this.handleClick = this.handleClick.bind(this);
}
handleClick() {
console.log("this > ", this);
}
render() {
return <div onClick={this.handleClick}>test</div>;
}
}
4.在定义阶段使用箭头函数绑定
class App extends React.Component {
handleClick = () => {
console.log("this > ", this);
};
render() {
return <div onClick={this.handleClick}>test</div>;
}
}
前三种都会因 App 组件的props或state 变化而重新触发渲染,使其渲染新的handleClick。第四种将handleClick抽离出赋值为变量,通过 this 指向存储函数,起到了缓存作用
而函数式组件一定会渲染
function App() {
const handleClick = () => {
console.log("Click");
};
return <div onClick={handleClick}>test</div>;
}
但是 useCallback 能缓存函数,让它”记住“
function App() {
const handleClick = useCallback(() => {
console.log("Click");
}, []);
return (
<div className="App">
<Demo handleClick={handleClick} />
</div>
);
}
但使用 useCallback 必须使用 shouldComponentUpdate 或者 React.memo 来忽略同样的参数重复渲染
所以单独使用 useCallback 是不能的,它需要和 React.memo 配合
function Demo(props) {
return <div onClick={props.handleClick}>test</div>;
}
const MemoDemo = memo(Demo);
function App() {
const handleClick = useCallback(() => {
console.log("Click");
}, []);
return (
<div className="App">
<Demo handleClick={handleClick} />
</div>
);
}
但是 useCallback 会使代码可读性变差,所以尽量不用 useCallback
不用 useCallback ,那怎么提高性能呢?
useMemo
作用:记忆组件。替代类组件的shouldComponentUpdate
useCallback 的功能完全可以由 useMemo 所取代,如果你想通过 useMemo 返回一个记忆函数也是完全可以的
useCallback(fn, deps) 相当于 useMemo(() => fn, deps)
例子:
const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);
默认情况下,如果 React 父组件重新渲染,它包含的所有子组件都会重新渲染,即使子组件没有任何变化
useMemo 和 useCallback 接受的参数都是一样,都是在其依赖项发生变化后执行,都是返回缓存的值,区别在于 useMemo 返回的是函数运行的结果,useCallback 返回的是函数
useMemo 返回的是一个值,用于避免在每次渲染时都进行高开销的计算
useCallback VS useMemo
相同点:useCallback 和 useMemo 都是性能优化的手段,类似于类组件的 shouldComponentUpdate,在子组件中使用 shouldComponentUpdate,判断该组件的 props 和 state 有没有变化,从而避免每次父组件 render 时重新渲染子组件
区别:useCallback 和 useMemo 的区别是 useCallback 返回一个函数,当把它返回的这个函数作为子组件使用时,可以避免每次父组件更新时重新渲染这个子组件
memo
作用:避免重新渲染
只有当 props 改变时会重新渲染子组件
被 memo 包裹住后,当 props 不变时,子组件就不会渲染
React.memo() 方法可以防止子组件不必要渲染,从而提供组件性能。
关于性能优化 Dan 曾写过一篇文章:在你写memo()之前,其实在我们使用 useCallback、useMemo、memo前不妨试试 state 下移和内容提升。目的就是让不用渲染的组件不重复渲染
useRef
作用:
保存引用值,跟 createRef 类似。我们习惯用 ref 保存 DOM
使用 useRef 保存和更新一些数据是有一定好处的,它可以不通过内存来保存数据,使得这些数据再重渲染时不会被清除掉
它不仅仅是用来管理DOM ref 的,它还相当于 this,可以存放任何变量,很好的解决闭包带来的不方便性
如果我们想利用普通的变量再重渲染过程中追踪数据变化是不可行的,因为每次组件渲染时它都会被重新初始化。然而,如果使用 ref 的话,其中的数据能在每次组件渲染时保持不变。
例子:
const [count, setCount] = useState < number > 0;
const countRef = useRef < number > count;
在函数式组件与类组件有何不同介绍过使用方法
其他
useContext:减少组件层级
useReducer: 类 redux 的方法,useState 是基于它扩张的
ForwardRef:转发 ref
useImperativeHandle :透传 Ref,父组件获取子组件内的方法
自定义 Hooks
由于 useState 和 useEffect 是函数调用,因为我们可以将其组合成自己的 Hooks
function MyResponsiveComponent() {
const width = useWindowWidth();
return <p> Window width is {width}</p>;
}
function useWindowWidth() {
const [width, setWidth] = useState(window, innerWidth);
useEffect(() => {
const handleResize = () => setWidth(window.innerWidth);
window.addEventListener("resize", handleResize);
return () => {
window.removeEventListener("resize", handleResize);
};
});
return width;
}
自定义 Hooks 让不同的组件共享可重用的状态逻辑。注意状态本身是不共享的。每次调用 Hook 都只声明了其自身的独立状态
React Hooks的不足
虽然实现了大多数类组件的功能,但是还无法实现 getSnapshotBeforeUpdate 和 componentDidCatch 这两个 API
附录:使用规则
Hooks 的本质就是 JavaScript 函数,在使用它时需要遵守两条规则
只在最顶层使用 Hook
不要在循环,条件或嵌套函数中调用 Hook,确保总是在你的 React 函数的最顶层以及任何 return 之前调用他们。遵守这条规则,你就能确保 Hook 在每次渲染中都按照同样的顺序被调用。这让 React 能够在多次的 useState 和 useEffect 调用之间保持 hook 状态的正确
只在 React 函数中调用 Hook
不要再普通的 JavaScript 函数中调用 Hook,你可以:
- 在 React 的函数组件中调用 Hook
- 在自定义 Hook 中调用其他 Hook
参考资料